

【应用】撩开分布式存储神秘面纱
VBS是计算数据块存储位置的重要网元。一个VBS就是一个“机头”。VBS部署很灵活,有很多种部署方法,可以根据不同的需求进行选择。比如,在VMWARE虚拟机中,可以在物理机上开设一台虚拟机部署VBS,在XEN/KVM部署在domain0上;或者部署在每台OSD服务器上,或专门设置VBS服务器群。

VBS采取一致性哈希算法,如图3,将数据块的逻辑地址计算出KEY值。并将计算出来的KEY映射到哈希环上,在哈希环上划分了N段(Partition),每个Partition对应一个硬盘,并根据出partition主和osd节点的映射关系ioview,和partitio主备对应的osd关系,得到该数据块的路由,如图4。在写入的时候,采用强一致性,即当主和备副本都返回写成功后,才认为这个IO写成功了。读IO时只读主副本,当主副本故障的时候,会在备副本中选举出主副本。目前,一个资源池可以支持2000块硬盘。

操作系统看到的连续的数据逻辑地址(LBA),实际上被打散到资源池内所有硬盘上了,类似所有硬盘都做了raid0,这样就利用了所有磁盘的性能,提高了存储的性能。操作系统实际是直接读写物理磁盘的块,并没有封装额外的文件系统,是一个raw设备。
OSD是一台插了较多硬盘的X86服务器,我们采用的是12块SATA3T的硬盘作为数据的持久化存储介质。如果VBS不承载在OSD上,那么OSD服务器的计算压力实际上很小,也没有必要配置计算能力很强、内存配置很高的服务器。上一篇文章计算过,12块SATA盘提供的iops或吞吐量其实很有限,需要配置SSD作为缓存,加速存储的性能。由此看来,分布式存储的性能是由SSD的性能和热点数据计算算法决定的。和一般存储不同,一般分布式存储的写性能会好于读性能。主要是主和备副本写入SSD就返回成功了,而SSD什么时候写入硬盘,怎么写入硬盘,客户端是不知道的。而读数据的时候,如果数据是热点数据,已经在缓存在SSD上,性能会很好,如果没有在缓存中,就需要到硬盘中直接读取,那性能就很差了。这也是当分布式存储在初始化的时候,测试性能指标不如运行一段时间后的指标。所以测试分布式存储有很多陷阱,大家要注意。
为了提高存储的安全性,达到6个9以上的安全性,我们采取的是通行的3副本(2副本在96块盘以下,可以达到6个9)。副本可以根据实际情况设置成为在不同机架、不同服务器、不同硬盘的安全级别。当磁盘或主机故障,会被MDC监控到,会选举主副本、踢出故障点、重构副本等操作。为了确保数据的安全,副本重构的时间很关键,我们要求,每T数据重构时间不超过30分钟。
为了确保数据重构流量不影响正常存储IO访问流量,实现快速数据重构。我们没有采取华为推荐的网络方案,而是采用环形虚拟化堆叠的方案,交换机间的堆叠链路采用40G光路,如图5。将存储的重构流量都压制在存储环形网络中。交换机到服务器采用2*10G连接,可以根据情况采用主备或分担的模式。

说过了“块”存储,再简单了解一下“对象存储”。对象存储是在同样容量下提供的存储性能比文件存储更好,又能像文件存储一样有很好的共享性。实际使用中,性能不是对象存储最关注的问题,需要高性能可以用块存储,容量才是对象存储最关注的问题。所以对象存储的持久化层的硬盘数量更多,单盘的容量也更大。对象存储的数据的安全性保障也各式各样,可以是单机raid或网络raid,也可以副本。对性能要求不高,可以直接用普通磁盘,或利用raid卡的缓存,也可以配些SSD作为缓存。我们现在使用单机35块7200转4TSATA盘+raid卡缓存加速的自研对象存储,并计划在今年使用60块7200转8TSATA盘。即每台服务器提供480T的裸容量。Ceph和google基于GFS的存储就是典型的对象存储。
Ceph是目前最为热门的存储,可以支持多种接口。Ceph存储的架构和华为的FusionStorage异曲同工,都是靠“算”而不是“查”。一种是为数众多的、负责完成数据存储和维护功能的OSD,另一种则是若干个负责完成系统状态检测和维护的monitor。OSD和monitor之间相互传输节点状态信息,共同得出系统的总体工作状态,并形成一个全局系统状态记录数据结构,即所谓的clustermap。这个数据结构与特定算法相配合,便实现了Ceph“无需查表,算算就好”的核心机制以及若干优秀特性。
但数据的的组织方法是不同的。首先ceph的核心是一个对象存储,是以对象为最小组织单位。1、首先文件是被映射成为一个或多个对象。2、然后每个对象再被映射到PG(PlacementGroup)上,PG和对象之间是“一对多”映射关系。3、而PG会映射到n个OSD上,n就是副本数,OSD和PG是“多对多”的关系。
由若干个monitor共同负责整个Ceph集群中所有OSD状态的发现与记录,并且共同形成clustermap的master版本,然后扩散至全体OSD以及客户端。OSD使用clustermap进行数据的维护,而客户端使用clustermap进行数据的寻址。
Google三大宝之一的“GFS”是google对象存储的基础。
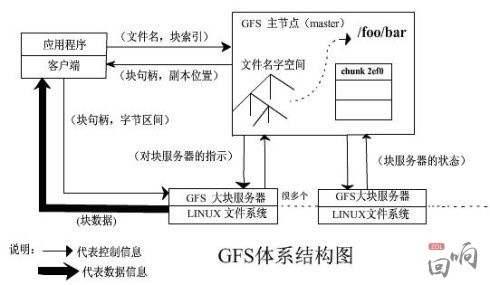
核心不同是数据的组织架构:master服务器(即元数据服务器)保存了文件名和块的名字空间、从文件到块的映射、副本位置,由客户端来查询。是一个典型的信令和媒体分开的架构。
分布式存储一般情况下都是靠“副本”来确保数据的安全性和完整性。每块盘记录的数据内容都不一样,当某一块盘出现问题,都需要从其他不同盘内的数据块中进行快速的数据重构。数据重构是需要时间的,如果大量盘同时故障,将会发生什么?另外,OSD的扩容,也会导致数据的迁移,也会影响存储。下一篇,我将最终揭开分布式存储存在的隐患。

责任编辑:蒋桂云
-

亚坦新能:技术驱动光伏
2018-04-13光伏 -

【户外必备】Biolite随时能充电的太阳能板
-

超级电容器在分布式微电网中的应用







-
【应用】撩开分布式存储神秘面纱
-
亚坦新能:技术驱动光伏
2018-04-13光伏 -
【户外必备】Biolite随时能充电的太阳能板
