
UNICODE编程实现软件的国际化
摘 要:本文对UNICODE字符集作详细介绍,并对基于Window 2000以上的WIN32操作系统在Visual C++编程环境下实现软件的多国语言作详细论述。关键词:UNICODE 编码 MBCS SBCS 对于中东等非英语国家的地区,
摘 要:本文对UNICODE字符集作详细介绍,并对基于Window 2000以上的WIN32操作系统在Visual C++编程环境下实现软件的多国语言作详细论述。

关键词:UNICODE 编码 MBCS SBCS
对于中东等非英语国家的地区,用户经常要编写双语或多语操作界面。并且从Windows NT操作系统后,即使输入的MBCS字符,操作系统也要转换为UNICODE字符,并且有必要输出时还要经过一次UNICODE到MBCS字符集的转换,虽然系统已经做了极大的优化,但还是有速度损失的。鉴于此,UNICODE编程似乎势在必行。
1 UNICODE概述
UNICODE 是目前用来解决 ASCII 码 256 个字符限制问题的一种比较流行的解决方案。ASCII 字符集只有256个字符,用 0-255 之间的数字来表示。包括大小写字母、数字以及少数特殊字符;如标点符号、货币符号等。对于大多数拉丁语言来说,这些字符已经够用。但是,许多亚洲和东方语言所用的字符远远不止256个字符,有些甚至超过万个。为了突破 ASCII 码字符数的限制,试图用一种简单的方法来针对超过256个字符的语言编写计算机程序,于是 UNICODE 应运而生。
2 字符编码
第一种编码类型是单子节字符集SBCS(single-byte character set)。在这种编码模式下,所有的字符都只用一个字节表示。ASCII是SBCS。一个字节表示的0用来标志SBCS字符串的结束符。
第二种编码模式是多字节字符集MBCS(multi-byte character set)。一个MBCS编码包含一些一个字节长的字符,而另一些字符大于一个字节的长度。用在Windows里的MBCS包含两种字符类型,单字节字符SBCS(single-byte characters set)和双字节字符DBCS(double-byte characters set)。由于Windows里使用的多字节字符绝大部分是两个字节长,所以MBCS常被用DBCS代替。
在DBCS编码模式中,一些特定的值被保留用来表明它们是双字节字符的一部分。例如,中文在GB2312编码中,一个大于0x7f的特定范围内的值表示这是一个双字节字符,紧跟着的下一个子节是这个字符的一部分。第一个值被称作"leading bytes"。跟随在一个leading byte子节后面的字节被称作"trail byte"。在DBCS中,trail byte可以是任意非0值。例如,在GB2312编码集中,“论”的“leading bytes”为“0xCB”, “trail byte”为“0xDB”。同SBCS一样,DBCS字符串的结束标志也是一个单字节表示的0。
第三种编码模式是Unicode。Unicode是一种所有的字符都使用两个字节编码的编码模式。Unicode字符有时也被称作宽字符,因为它比单子节字符宽(使用了更多的存储空间)。“论”的UNICODE编码为0x8bba。注意,Unicode不能被看作MBCS。MBCS的独特之处在于它的字符使用不同长度的字节编码。Unicode字符串使用两个字节表示的0作为它的结束标志。
3 UNICODE编程的实现
本节结合制作英文/阿拉伯文双语界面来讨论利用UNICODE编程的具体实现过程。
3.1 字符串的定义
对于MBCS编程,定义一个字符串的常用格式:
char buf[100];
字符串的拷贝函数下面这样声明函数原形:
void strcpy( char *out, char *in );
为了将上面的声明改成支持双字节的 UNICODE 字符集,可以用下面的方法:
wchar_t str[100];
相应的字符串的拷贝函数下面这样声明函数原形:
void wcscpy ( wchar_t *out, wchar_t *in );
这样定义显然比较麻烦,有幸的是Visual C++定义了一个“新”的数据类型TCHAR,这个类型会根据预处理宏指令转换为相应得字符集所需类型,也就是若定义了UNICODE,_UNICODE预处理宏指令了的话,TCAHR就是wchar_t,若定义了MBCS,_MBCS的话他就是char。同样,MBCS字符串处理函数str*(…)都用_tcs*(…)替代,这样就为编程带来极大的方便。
相应的,字符串常量用_T()或TEXT()重写。
例如_T(“hello!”)或TEXT(“hello!”);
或者直接在字符串常量前加L,例如L”hello!”。
下表是数据类型在不同的编译环境下所对应的类型。
3.2 编译器设置和文件存储方式
3.2.1 编译器设置
利用UNICODE编程必须定义UNICODE,_UNICODE预处理宏指令,注意,这里的 UNICODE 和 _UNICODE 必须都要定义,那它们有什么区别呢?前者没有下划线,专门用于 Windows 头文件;后者有一个前缀下划线,专门用于 C 运行时头文件。
3.2.2 文件存储格式
如果在源文件中出现阿拉伯文就必须将存为UNICODE格式,否则文件在下一次打开后输入阿文的地方会出现“?”,就是说如果文件存为ASCII的话,存储的阿文字符无法识别。
在Visual C++ 6.0的存储格式没有UNICODE存储格式,可以用记事本等文本编辑工具将源文件打开选择另存,并在格式康宝框中把格式选为Unicode即可。对于Visual C++ 7.0以上版本,在IDE中另存该文件并选择编码UNICODE(代码页1200)保存即可。
3.3 双语界面的实现
古老的方法是判断程序中一个语言标志变量,例如g_lang,利用该变量动态的更改控件、对话框等资源的英/阿文的显示,这对于大型软件来说工作量是相当大的。幸好,微软提供了纯资源的动态链接库,只要将资源文件编译成英文的动态链接库eng.dll和阿文的动态链接库arb.dll,这样在切换语言是卸载当前库,加载另一个语言库就完成了双语的实时切换。须在应用程序类的InitInstance函数中加入如下代码:
if(g_lang=='a') //阿文界面
m_hInstRes=::LoadLibrary(L"arb.dll");
else //英文界面
m_hInstRes=::LoadLibrary(L"eng.dll");
if (m_hInstRes == NULL)
{
AfxMessageBox(L"Cannot open Resource file(dll).");
return FALSE; // failed to load the localized resources
}
else
{
AfxSetResourceHandle(m_hInstRes); // get resources from the DLL
}
在ExitInstance()函数中加入:
if(m_hInstRes)
::FreeLibrary(m_hInstRes);
这样就实现了语言库的加载。并用代码在语言实时切换处动态卸载,加载所需库即可。
阿文纯资源的动态链接库的编写比较麻烦,因为Visual C++的资源编辑器不支持UNICODE的字符输入。用记事本或其它文本编辑软件打开工程目录下的资源文件(扩展名为rc)仔细查看,发现都有code_page的定义,也就是说,它采用的是MBCS编码,根据不同的代码页,将字符串转化为当前代码页所对应的字符串。例如,当code_page为1252(中文代码页)时,“论”显示的就是“论”,而在code_page为936(英文代码页)时,他将显示的是乱码。阿文(阿尔及利亚)的代码是1256。
这就需要两个WIN APIs 函数WideCharToMultiByte和MultiByteToWideChar,前者是将UNICODE转化为MBCS,后者恰好相反,具体参数请参考MSDN。笔者作了个小装换程序,在一个编辑框中输入阿拉伯文(此时编码为UNICODE),点击转换按钮后转化为该段阿拉伯字符的MBCS编码,将这段“乱码”copy到资源编辑器的相对应的英文的位置上,即可正常显示阿文了。
4 结语
综上所述可以看到,编译 UNICODE 版本的程序并不难,只是在编写代码时记住函数调用上细微的变化。微软为此提供的扩展使开发人员能够以透明的方式选择所用的字符集,为应用软件的国际化打开了方便之门。

责任编辑:叶雨田
免责声明:本文仅代表作者个人观点,与本站无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
我要收藏
个赞
-

现货模式下谷电用户价值再评估
2020-10-10电力现货市场,电力交易,电力用户 -

PPT | 高校综合能源服务有哪些解决方案?
2020-10-09综合能源服务,清洁供热,多能互补 -

深度文章 | “十三五”以来电力消费增长原因分析及中长期展望
2020-09-27电力需求,用电量,全社会用电量
-
PPT | 高校综合能源服务有哪些解决方案?
2020-10-09综合能源服务,清洁供热,多能互补 -
深度文章 | “十三五”以来电力消费增长原因分析及中长期展望
2020-09-27电力需求,用电量,全社会用电量 -
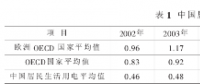
我国电力改革涉及的电价问题


-

贵州职称论文发表选择泛亚,论文发表有保障
2019-02-20贵州职称论文发表 -

《电力设备管理》杂志首届全国电力工业 特约专家征文
2019-01-05电力设备管理杂志 -

国内首座蜂窝型集束煤仓管理创新与实践
-

人力资源和社会保障部:电线电缆制造工国家职业技能标准
-

人力资源和社会保障部:变压器互感器制造工国家职业技能标准
-

《低压微电网并网一体化装置技术规范》T/CEC 150
2019-01-02低压微电网技术规范
-
现货模式下谷电用户价值再评估
2020-10-10电力现货市场,电力交易,电力用户 -
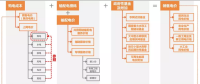
建议收藏 | 中国电价全景图
2020-09-16电价,全景图,电力 -
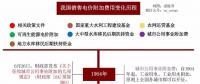
一张图读懂我国销售电价附加
2020-03-05销售电价附加
-

电气工程学科排行榜发布!华北电力大学排名第二
-

国家电网61家单位招聘毕业生
2019-03-12国家电网招聘毕业生 -

《电力设备管理》杂志读者俱乐部会员招募
2018-10-16电力设备管理杂志
